(1) Informazioni ridondanti del segnale video
Prendendo come esempio il formato componente YUV della registrazione di video digitale, YUV rappresenta rispettivamente la luminosità e due segnali di differenza di colore. Ad esempio, per il sistema pal TV esistente, la frequenza di campionamento del segnale di luminanza è 13.5 mhz; la banda di frequenza del segnale di crominanza è solitamente la metà o meno del segnale di luminosità, che è 6.75 mhz o 3.375 mhz. Prendendo come esempio la frequenza di campionamento di 4: 2: 2, il segnale Y adotta 13.5 mhz, il segnale di crominanza U e V vengono campionati da 6.75 mhz e il segnale di campionamento viene quantizzato di 8 bit, quindi è possibile calcolare la velocità di codice del video digitale come segue:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216 Mbit / s
Se una quantità così grande di dati viene archiviata o trasmessa direttamente, sarà difficile utilizzare la tecnologia di compressione per ridurre il bit rate. Il segnale video digitale può essere compresso secondo due condizioni fondamentali:
L. ridondanza dei dati. Ad esempio, ridondanza spaziale, ridondanza temporale, ridondanza della struttura, ridondanza dell'entropia delle informazioni, ecc., Ovvero, esiste una forte correlazione tra i pixel dell'immagine. L'eliminazione di queste ridondanze non comporta la perdita di informazioni ed è una compressione senza perdite.
L. ridondanza visiva. Alcune caratteristiche degli occhi umani, come la soglia di discriminazione della luminosità, la soglia visiva, sono diverse per sensibilità alla luminosità e alla crominanza, il che rende impossibile introdurre errori appropriati nella codifica e non verranno rilevate. Le caratteristiche visive degli occhi umani possono essere utilizzate per scambiare la compressione dei dati con una certa distorsione oggettiva. Questa compressione è con perdita.
La compressione del segnale video digitale si basa sulle due condizioni precedenti, il che rende i dati video notevolmente compressi, favorendo la trasmissione e l'archiviazione. I metodi comuni di compressione video digitale sono la codifica mista, che consiste nel combinare la codifica della trasformazione, la stima del movimento e la compensazione del movimento e la codifica entropica per comprimere la codifica. Di solito, la codifica della trasformazione viene utilizzata per eliminare la ridondanza intra-frame dell'immagine e la stima del movimento e la compensazione del movimento vengono utilizzate per rimuovere la ridondanza inter-frame dell'immagine e la codifica entropica viene utilizzata per migliorare ulteriormente l'efficienza di compressione. I seguenti tre metodi di codifica della compressione vengono introdotti brevemente.
(a) Metodo di codifica a compressione
(b) Trasforma la codifica
La funzione della codifica della trasformata è trasformare il segnale dell'immagine descritto nel dominio dello spazio nel dominio della frequenza e quindi codificare i coefficienti trasformati. In generale, l'immagine ha una forte correlazione nello spazio e la trasformazione nel dominio della frequenza può realizzare la decorrelazione e la concentrazione di energia. La trasformazione ortogonale comune include la trasformata discreta di Fourier, la trasformata discreta del coseno e così via. La trasformazione discreta del coseno è ampiamente utilizzata nella compressione video digitale.
La trasformata discreta del coseno viene definita trasformata DCT. Può trasformare il blocco dell'immagine di L * l dal dominio dello spazio al dominio della frequenza. Pertanto, nel processo di compressione e codifica dell'immagine basata su DCT, l'immagine deve essere suddivisa in blocchi immagine non sovrapposti. Supponiamo che la dimensione di un'immagine sia 1280 * 720, è divisa in blocchi immagine 160 * 90 con dimensioni 8 * 8 senza sovrapposizione sotto forma di griglia. Quindi la trasformazione DCT può essere eseguita per ogni blocco immagine.
Dopo che il blocco è stato diviso, ogni blocco immagine a 8 * 8 punti viene inviato al codificatore DCT e il blocco immagine 8 * 8 viene trasformato dal dominio spaziale al dominio della frequenza. La figura seguente mostra un esempio di un blocco immagine di 8 * 8 in cui il numero rappresenta il valore di luminosità di ogni pixel. Si può vedere dalla figura che i valori di luminosità di ciascun pixel in questo blocco di immagine sono relativamente uniformi, in particolare il valore di luminosità dei pixel adiacenti non è molto grande, il che indica che il segnale dell'immagine ha una forte correlazione.
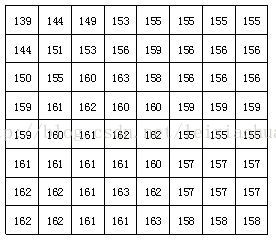
Un vero e proprio blocco di immagini 8 * 8
La figura seguente mostra i risultati della trasformazione DCT del blocco immagine nella figura sopra. Si può vedere dalla figura che dopo la trasformazione DCT, il coefficiente di bassa frequenza nell'angolo in alto a sinistra concentra molta energia, mentre l'energia sul coefficiente di alta frequenza nell'angolo in basso a destra è molto piccola.
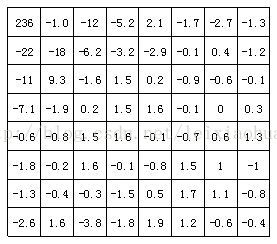
I coefficienti del blocco dell'immagine dopo la trasformazione DCT
Il segnale deve essere quantificato dopo la trasformazione DCT. Poiché gli occhi umani sono sensibili alle caratteristiche a bassa frequenza delle immagini, come la luminosità complessiva degli oggetti, e non ai dettagli ad alta frequenza nell'immagine, quindi nel processo di trasmissione, le informazioni ad alta frequenza possono essere trasmesse meno o meno, solo la parte a bassa frequenza. Il processo di quantizzazione riduce la trasmissione delle informazioni quantificando i coefficienti della regione a bassa frequenza e la quantizzazione grossolana dei coefficienti nella regione ad alta frequenza, che rimuove le informazioni ad alta frequenza che non sono sensibili agli occhi umani. Pertanto, la quantizzazione è un processo di compressione con perdita e la ragione principale del danno alla qualità nella codifica della compressione video.
Il processo di quantificazione può essere espresso dalla seguente formula:

Tra questi, FQ (U, V) rappresenta il coefficiente DCT dopo la quantizzazione; f (U, V) rappresenta il coefficiente DCT prima della quantizzazione; Q (U, V) rappresenta la matrice di ponderazione di quantizzazione; q è il passo di quantizzazione; round si riferisce al consolidamento e il valore da produrre viene considerato come il valore intero più vicino.
Selezionare ragionevolmente il coefficiente di quantizzazione e il risultato dopo la quantizzazione del blocco immagine trasformato viene mostrato nella figura.

Coefficiente DCT dopo quantificazione
La maggior parte dei coefficienti DCT viene modificata in 0 dopo la quantizzazione, mentre solo pochi coefficienti sono valori diversi da zero. A questo punto, solo questi valori diversi da zero devono essere compressi e codificati.
(b) Codifica entropica
La codifica entropica è denominata perché la lunghezza media del codice dopo la codifica è vicina al valore di entropia della sorgente. La codifica entropica è implementata da VLC (codifica a lunghezza variabile). Il principio di base è quello di dare un codice breve al simbolo con alta probabilità nella sorgente, e di dare un codice lungo al simbolo con una piccola probabilità di accadimento, in modo da ottenere statisticamente la lunghezza media del codice più breve. La codifica a lunghezza variabile di solito include codice Hoffman, codice aritmetico, codice di esecuzione, ecc. La codifica della lunghezza di esecuzione è un metodo di compressione molto semplice, la sua efficienza di compressione non è elevata, ma la velocità di codifica e decodifica è veloce ed è ancora ampiamente utilizzata, soprattutto dopo la trasformazione della codifica, utilizzando la codifica run-length, ha un buon effetto.
Innanzitutto, il coefficiente AC immediatamente successivo al coefficiente DC di uscita del quantizzatore deve essere scansionato in tipo Z (come mostrato nella linea della freccia). Lo Z-scan trasforma il coefficiente di quantizzazione bidimensionale in una sequenza unidimensionale, quindi prosegue la codifica della lunghezza della corsa. Infine, un altro codice a lunghezza variabile viene utilizzato per codificare i dati dopo la codifica di esecuzione, come la codifica Hoffman. Grazie a questo tipo di codifica a lunghezza variabile, l'efficienza della codifica è ulteriormente migliorata.
(c) Stima del movimento e compensazione del movimento
La stima del movimento e la compensazione del movimento sono metodi efficaci per eliminare la correlazione della direzione temporale delle sequenze di immagini. I metodi di trasformazione DCT, quantizzazione e codifica entropica descritti sopra si basano su un'immagine di fotogramma. Attraverso questi metodi, la correlazione spaziale tra i pixel nell'immagine può essere eliminata. Infatti, oltre alla correlazione spaziale, il segnale dell'immagine ha una correlazione temporale. Ad esempio, per i video digitali con sfondo statico come la trasmissione di notiziari e piccoli movimenti del corpo principale dell'immagine, la differenza tra ciascuna immagine è molto piccola e la correlazione tra le immagini è molto grande. In questo caso, non abbiamo bisogno di codificare ogni immagine di fotogramma separatamente, ma possiamo codificare solo le parti modificate di fotogrammi video adiacenti, in modo da ridurre ulteriormente la quantità di dati. Questo lavoro è realizzato dalla stima del movimento e dalla compensazione del movimento.
La tecnologia di stima del movimento generalmente divide l'immagine in ingresso corrente in diversi piccoli sottoblocchi dell'immagine che non si sovrappongono tra loro, ad esempio, la dimensione di un'immagine del fotogramma è 1280 * 720. In primo luogo, è divisa in 40 * 45 blocchi immagine con 16 * 16 dimensioni che non si sovrappongono tra loro sotto forma di griglia, quindi, nell'ambito di una finestra di ricerca dell'immagine precedente o di quest'ultima immagine, trova un blocco per ogni blocco immagine per trovare un blocco immagine nell'ambito di un finestra di ricerca Il blocco di immagini più simile. Il processo di ricerca è chiamato stima del movimento. Calcolando le informazioni sulla posizione tra il blocco immagine più simile e il blocco immagine, è possibile ottenere un vettore di movimento. In questo modo, il blocco immagine corrente può essere sottratto dal blocco immagine più simile indicato dal vettore di movimento dell'immagine di riferimento e si può ottenere un blocco immagine residuo. Poiché ogni valore di pixel nel blocco dell'immagine residua è molto piccolo, è possibile ottenere un rapporto di compressione più elevato nella codifica di compressione. Questo processo di sottrazione è chiamato compensazione del movimento.
Poiché è necessario utilizzare l'immagine di riferimento per la stima del movimento e la compensazione del movimento nel processo di codifica, è molto importante selezionare l'immagine di riferimento. Generalmente, il codificatore divide ogni immagine di frame in ingresso in tre diversi tipi in base alle diverse immagini di riferimento: frame I (intra), frame B (previsione di guida) e frame P (predizione). Come mostrato in figura.
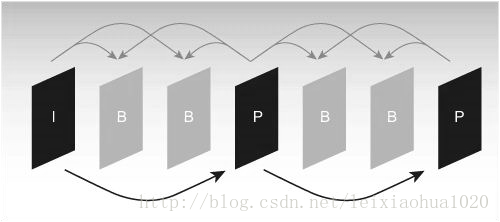
Tipica sequenza della struttura del frame I, B, P.
Come mostrato nella figura, I frame utilizza solo i dati nel frame per la codifica e non necessita di stima del movimento e compensazione del movimento durante il processo di codifica. Ovviamente, poiché I frame non elimina la correlazione della direzione del tempo, il rapporto di compressione è relativamente basso. Nel processo di codifica, il fotogramma P utilizza un fotogramma I anteriore o un fotogramma P come immagine di riferimento per la compensazione del movimento, infatti codifica la differenza tra l'immagine corrente e l'immagine di riferimento. La modalità di codifica del fotogramma B è simile al fotogramma P, l'unica differenza è che deve utilizzare un fotogramma I anteriore o un fotogramma P e un fotogramma I successivo o fotogramma P per prevedere durante il processo di codifica. Pertanto, ogni codifica di frame P deve utilizzare un'immagine di frame come immagine di riferimento, mentre il frame B necessita di due frame come riferimento. Al contrario, il frame B ha un rapporto di compressione più elevato rispetto al frame P.
(d) Codifica mista
Il documento introduce diversi metodi importanti nella compressione e codifica video. Nell'applicazione pratica, questi metodi non sono separati e di solito vengono combinati per ottenere il miglior effetto di compressione. La figura seguente mostra il modello di codifica ibrida (cioè codifica trasformata + stima del movimento e compensazione del movimento + codifica entropica). Il modello è ampiamente utilizzato in MPEG1, MPEG2, H.264 e altri standard. Dalla figura, possiamo vedere che l'immagine corrente in ingresso deve essere prima divisa in blocchi, il blocco dell'immagine ottenuto dal blocco deve essere sottratto dal immagine prevista dopo la compensazione del movimento per ottenere l'immagine della differenza x, quindi vengono eseguite la trasformazione DCT e la quantizzazione per il blocco dell'immagine della differenza. I dati di output quantizzati hanno due posizioni diverse: una è l'invio al codificatore entropico per la codifica e il flusso di codice codificato viene emesso in una cache Salva nel dispositivo e attende la trasmissione. Un'altra applicazione consiste nel contrastare quantificare e invertire la modifica al segnale x ', che aggiunge l'uscita del blocco immagine con la compensazione del movimento per ottenere un nuovo segnale dell'immagine di previsione e invia un nuovo blocco dell'immagine di previsione alla memoria del frame.



|
|
|
|
Fino a che punto (lungo) il coperchio del trasmettitore?
Il raggio di trasmissione dipende da molti fattori. La distanza reale si basa sulla antenna installazione altezza, guadagno di antenna, utilizzando ambiente come costruzione ed altri ostacoli, sensibilità del ricevitore, antenna del ricevitore. Installazione antenna più alta e l'utilizzo in campagna, la distanza sarà molto più lontano.
ESEMPIO 5W trasmettitore FM utilizzare in città e città natale:
Ho un uso del cliente 5W trasmettitore FM con antenna GP USA nella sua città natale, e lui prova con una macchina, coprire 10km (6.21mile).
I test il trasmettitore FM 5W con antenna GP nella mia città natale, che coprono circa il 2km (1.24mile).
I test il trasmettitore FM 5W con antenna GP nella città di Guangzhou, che coprono circa il solo 300meter (984ft).
Qui di seguito sono la gamma approssimativa di diversi trasmettitori di potenza FM. (L'intervallo è di diametro)
0.1W ~ 5W Trasmettitore FM: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W Trasmettitore FM: 3KM ~ 10KM
80W ~ 500W Trasmettitore FM: 10KM ~ 30KM
500W ~ 1000W Trasmettitore FM: 30KM ~ 50KM
1KW ~ 2KW Trasmettitore FM: 50KM ~ 100KM
2KW ~ 5KW Trasmettitore FM: 100KM ~ 150KM
5KW ~ 10KW Trasmettitore FM: 150KM ~ 200KM
Come contattarci per il trasmettitore?
Call me + 8618078869184 O
Se la tua attività ha avuto un impatto negativo e posso esserti di aiuto, mi piacerebbe aiutarti., Mandami un'email [email protected]
1.How lontano si vuole coprire di diametro?
2.How alto di voi Tower?
3.Where sei?
E vi daremo consigli più professionale.
Chi siamo
FMUSER.ORG è una società di integrazione di sistemi che si occupa di trasmissione wireless RF / apparecchiature audio video da studio / streaming e elaborazione dati. Forniamo tutto, dalla consulenza e consulenza attraverso l'integrazione del rack all'installazione, alla messa in servizio e alla formazione.
Offriamo trasmettitori FM, trasmettitori TV analogici, trasmettitori TV digitali, trasmettitori UHF VHF, antenne, connettori per cavi coassiali, STL, elaborazione in onda, prodotti Broadcast per lo studio, monitoraggio del segnale RF, codificatori RDS, processori audio e unità di controllo del sito remoto, Prodotti IPTV, codificatore / codificatore audio / video, progettato per soddisfare le esigenze sia delle grandi reti di trasmissione internazionali che di piccole stazioni private.
La nostra soluzione dispone di stazione radio FM / stazione TV analogica / stazione TV digitale / attrezzatura da studio audio video / collegamento trasmettitore da studio / sistema di telemetria del trasmettitore / sistema TV dell'hotel / trasmissione live IPTV / trasmissione live streaming / videoconferenza / sistema di trasmissione CATV.
Stiamo utilizzando prodotti di tecnologia avanzata per tutti i sistemi, perché sappiamo che l'alta affidabilità e le alte prestazioni sono così importanti per il sistema e la soluzione. Allo stesso tempo, dobbiamo anche assicurarci che il nostro sistema di prodotti abbia un prezzo molto ragionevole.
Abbiamo clienti di emittenti pubbliche e commerciali, operatori di telecomunicazioni e autorità di regolamentazione e offriamo anche soluzioni e prodotti a molte centinaia di emittenti minori, locali e comunitarie.
FMUSER.ORG esporta da più di 15 anni e ha clienti in tutto il mondo. Con 13 anni di esperienza in questo campo, abbiamo un team di professionisti per risolvere tutti i tipi di problemi dei clienti. Ci siamo impegnati a fornire prezzi estremamente ragionevoli di prodotti e servizi professionali. Contatto email : [email protected]
La nostra fabbrica

Abbiamo modernizzazione della fabbrica. Siete invitati a visitare la nostra fabbrica quando si arriva in Cina.

Allo stato attuale, ci sono già clienti 1095 in tutto il mondo visitato il nostro ufficio di Guangzhou Tianhe. Se venite in Cina, siete invitati a farci visita.
Alla Fiera

Questa è la nostra partecipazione a 2012 globali Fonti Hong Kong Electronics Fair . I clienti provenienti da tutto il mondo infine, avere la possibilità di stare insieme.
Dove è FMUSER?
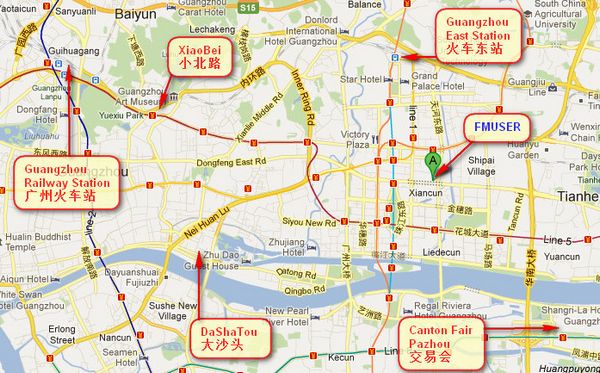
Puoi cercare questi numeri " 23.127460034623816,113.33224654197693 "in google map, puoi trovare il nostro ufficio fmuser.
ufficio FMUSER Guangzhou è nel quartiere Tianhe che è la centro del Cantone . Molto vicino Vai all’email la fiera di Canton , stazione ferroviaria di Guangzhou, strada Xiaobei e Dashatou , Solo bisogno 10 minuti se prendere TAXI . Benvenuti amici di tutto il mondo a visitare e negoziare.
Contatto: Blue Sky
Cellulare: + 8618078869184
WhatsApp: + 8618078869184
Wechat: + 8618078869184
E-mail: [email protected]
QQ: 727926717
Skype: sky198710021
Indirizzo: No.305 camera Huilan costruzione No.273 Huanpu Strada Guangzhou Cina Codice postale: 510620
|
|
|
|
Inglese: Accettiamo tutti i pagamenti, come PayPal, Carta di credito, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, se hai qualche domanda, per favore contattami [email protected] o WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Si consiglia di utilizzare Paypal per comprare i nostri articoli, il Paypal è un modo sicuro per acquistare su internet.
Ogni della nostra lista elemento della pagina in basso sulla parte superiore hanno un logo PayPal per pagare.
Carta di credito.Se non avete paypal, ma avete carta di credito, è anche possibile fare clic sul pulsante giallo PayPal per pagare con carta di credito.
-------------------------------------------------- -------------------
Ma se non hai una carta di credito e non avere un conto paypal o difficile ottenuto un accout PayPal, è possibile utilizzare il seguente:
Western Union.  www.westernunion.com www.westernunion.com
Pagare con Western Union a me:
Nome / Nome proprio: Yingfeng
Cognome / Cognome / Nome famiglia: Zhang
Nome completo: Yingfeng Zhang
Paese: China
Città: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Paga con T / T (bonifico bancario / trasferimento telegrafico / bonifico bancario)
Primi DATI BANCARIE (CONTO AZIENDA):
SWIFT BIC: BKCHHKHHXXX
Nome della banca: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Indirizzo bancario: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
CODICE BANCARIO: 012
Nome account: FMUSER INTERNATIONAL GROUP LIMITED
Conto NO. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Secondo DATI BANCARIE (CONTO AZIENDALE):
Beneficiario: FMuser International Group Inc
Numero di conto: 44050158090900000337
Banca del beneficiario: China Construction Bank Guangdong Branch
Codice SWIFT: PCBCCNBJGDX
Indirizzo: NO.553 Tianhe Road, Guangzhou, Guangdong, distretto di Tianhe, Cina
**Nota: quando trasferisci denaro sul nostro conto bancario, NON scrivere nulla nell'area dei commenti, altrimenti non saremo in grado di ricevere il pagamento a causa della politica del governo sul commercio internazionale.
|
|
|
|
* Sarà inviato in 1-2 giorni lavorativi in cui il pagamento chiaro.
* Invieremo al tuo indirizzo paypal. Se si desidera cambiare l'indirizzo, si prega di inviare il vostro indirizzo corretto e numero di telefono per la mia e-mail [email protected]
* Se i pacchetti è inferiore 2kg, ci sarà spedito via posta aerea, ci vorranno circa 15-25days a mano.
Se il pacchetto è più di 2kg, spediremo via lo SME, DHL, UPS, Fedex consegna veloce espresso, ci vorranno circa 7 ~ 15days alla tua mano.
Se il pacchetto più di 100kg, invieremo via DHL o trasporto aereo. Ci vorranno circa 3 ~ 7days alla tua mano.
Tutti i pacchetti sono forma Cina Guangzhou.
* Il pacco verrà inviato come "regalo" e verrà declassato il meno possibile, l'acquirente non dovrà pagare la "TASSA".
* Dopo la nave, vi invieremo una e-mail e vi darò il numero di tracking.
|
|
|
Per garanzia.
Contattaci --- >> Restituiscici l'articolo --- >> Ricevi e invia un'altra sostituzione.
Nome: Liu Xiaoxia
Indirizzo: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou in Cina.
ZIP: 510620
Telefono: + 8618078869184
Si prega di restituire a questo indirizzo e scrivere il vostro paypal indirizzo, nome, problema sulla nota: |
|
Il nostro altro prodotto:













